The long-standing wisdom is that RAID is not beneficial for Hadoop data nodes. This wisdom is traced back to the venerable Hadoop: The Definitive Guide, which cites a 2009 Apache forum posting from Yahoo! engineer Runping Qi reporting experimental results showing JBOD to be faster than RAID-0.
The reasons cited in the Hadoop book are:
- HDFS has redundancy anyway, and
- RAID-0 slows down the entire array to match the speed of the slowest drive in the array
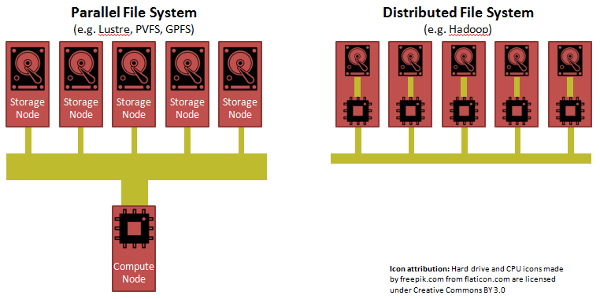
We can look toward "parallel" file systems from the world of High Performance Computing (HPC) for inspiration. The paradigm in HPC is to separate compute from storage, but to have a really fast network, but more importantly to have a "parallel file system". A parallel file system aggregates the bandwidth from many storage nodes to feed a compute node.
While Hadoop was able to achieve its performance through its clever insight of shipping code to data, each CPU in a Hadoop cluster has to suck its data from a single disk through a straw.
The limiting factor for both HPC and Hadoop is the slow transfer rate (1 Gbps) out of a hard drive. HPC addresses this bottleneck by:
- striping data across nodes,
- storing data across nodes in a round-robin fashion, rather than the more random approach that Hadoop takes
- using high-bandwidth links in the cluster (e.g. 40 Gbps Infiniband vs. 1 Gbps or 10 Gbps Ethernet
- using network DMA (Infiniband) instead of a heavy software stack (Ethernet)
There have been a couple chinks in the armor of the "No RAID for HDFS" received wisdom in the past couple of years. The book Pro Apache Hadoop, Second Edition, just published this month, provides one specific exception to the rule:
Some Hadoop systems can drop the replication factor to 2. One example is Hadoop running on the EMC Isilon hardware. The underlying rationale is that the hardware uses RAID 5, which provides a built-in redundancy, enabling a drop in replication factor. Dropping the replication factor has obvious benefits because it enables faster I/O performance (writing 1 replica less).Another is Hortonworks in 2012, which gives credence to the idea of using RAID-0, but at most only pairs of disks at a time.

It seems that we could have the best of both worlds if each node in a Hadoop cluster had parallel I/O across many disks, such as can be provided by RAID-0. As for the concern that RAID-0 is slowed to the speed of the slowest drive, well, the same is true of PVFS.
So should RAID-0 be used in Hadoop data nodes to speed up I/O to the CPU? Probably not, and here's why. CPUs for the past decade have plateaued on clock speed and have instead been adding cores. And there is a recommendation that there be a 1:1 ratio between "spindles to cores". For the purposes of I/O, multiple hard drives joined in RAID-0 would be considered a single spindle. So one could imagine a single 12-core CPU connected to 12 RAID-0 pairs, for a total of 24 drives. But as core count goes up over the upcoming years, and if dual- and quad-CPU motherboards are considered instead, this scenario becomes the exception.
No comments:
Post a Comment